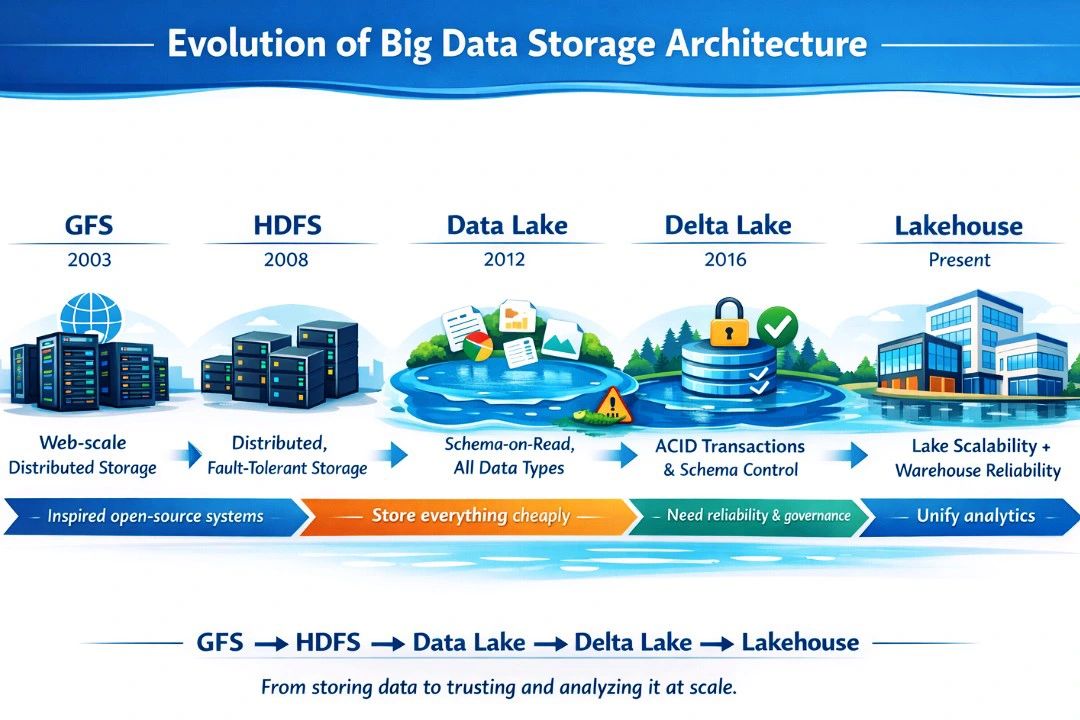
Como saímos do “armazenar a qualquer custo” até chegar no Lakehouse (sem pular etapas)
Durante anos, muita gente conta a história do Big Data como se o mundo tivesse ido de “banco de dados tradicional” direto para “Lakehouse”. Mas não foi assim.
- primeiro, armazenamento distribuído confiável,
- depois, escalabilidade de código aberto, em seguida, armazenamento barato e flexível,
- depois, transações e confiança, e, finalmente, uma única camada de armazenamento atendendo BI, streaming e ML. A evolução foi gradual — cada etapa nasceu para resolver um problema específico: escala, custo, flexibilidade, confiabilidade, governança e, por fim, a unificação de workloads (BI, streaming e ML) no mesmo dado.
A seguir, uma cronologia prática (com conceitos e exemplos reais) que explica por que chegamos onde chegamos.
1) Google File System (GFS) – O início da escala
Quando o Google começou a lidar com volumes gigantes de dados (indexação da web, logs de cliques, rastreamento de páginas “crawler”), o problema não era só “guardar muito”. Era guardar muito em hardware barato que quebrava — e continuar funcionando mesmo assim.
O que o GFS trouxe de novo
- Armazenamento distribuído: arquivos grandes quebrados em blocos e espalhados em várias máquinas.
- Tolerância a falhas: se um nó morre, o sistema se recupera.
- Replicação: múltiplas cópias dos dados para alta disponibilidade.
Exemplo de uso
- Armazenar trilhões de eventos de navegação para alimentar ranking e relevância de busca.
- Logs de sistemas distribuídos para auditoria e melhoria contínua. ✅ Legado: o GFS estabeleceu a “ideia base” para sistemas de arquivos distribuídos modernos.
2) HDFS – O GFS vira open source e nasce o ecossistema Hadoop
O HDFS (Hadoop Distributed File System) pegou o aprendizado do GFS e o levou para o mundo open source. Ele virou o “HD gigante” de clusters Hadoop.
Por que o HDFS foi tão importante
- Tornou o armazenamento distribuído acessível para empresas fora do Google.
- Trabalhou muito bem com processamento batch (MapReduce e, depois, Spark).
- Foi desenhado para arquivos grandes e leitura sequencial, o que combina com ETLs e processamento em lote.
Exemplo de uso
- Telecom: armazenar CDRs (Call Detail Records) e gerar relatórios diários de consumo.
- E-commerce: processar logs do site durante a madrugada para atualizar dashboards e relatórios operacionais.
Limitações que apareceram
- Forte acoplamento com cluster (infra mais “pesada”).
- Governança e consumo por BI ainda eram difíceis.
- Mudanças e updates (tipo “atualizar registros”) não eram naturais. ✅ Legado: HDFS “popularizou” Big Data e virou o backbone do Hadoop.
3) Data Lake – Tudo no mesmo lugar, barato e flexível… até virar pântano
Com a popularização de storage mais barato (incluindo object storage), as empresas começaram a pensar:
“Por que não guardar tudo — estruturado, semi-estruturado e não estruturado — num repositório único?”
Nasce o Data Lake, com a promessa de custo baixo e flexibilidade.
Conceitos-chave
- Schema-on-read: o dado é guardado “como veio” e o esquema é aplicado na leitura.
- Suporta múltiplos formatos: CSV, JSON, Parquet, ORC, Avro…
- Ideal para armazenar dados de diferentes sistemas sem “forçar” modelagem na ingestão.
Exemplo de uso
- Centralizar: eventos de clickstream (JSON),
- logs de aplicação,
- exportações de ERP/CRM,
- dados de IoT,
- arquivos de parceiros (CSV/Excel).
Por que muitos Data Lakes viraram “Data Swamps”
O problema não foi guardar tudo. Foi guardar sem disciplina:
- Sem catálogo/metadata (ninguém sabe o que existe).
- Sem padrões de nomenclatura, particionamento e formatos.
- Sem controle de qualidade (duplicidade, dado faltando, etc.).
- Sem controle de acesso consistente.
- Sem rastreabilidade/auditoria de mudanças. ✅ Legado: o Data Lake abriu o jogo para armazenar tudo e experimentar… mas expôs o preço da falta de governança.
4) Delta Lake – O Data Lake ganha “regras de banco”: transações, confiança e histórico
A evolução natural foi:
“E se eu mantiver a escalabilidade e o custo do Data Lake, mas com confiabilidade de banco de dados?”
Aí entram tecnologias como Delta Lake (e, no mercado, outras alternativas similares como Iceberg/Hudi). A ideia é transformar arquivos em uma camada confiável para analytics.
O que muda na prática
- ACID transactions: garante consistência (não “quebra” a tabela no meio de uma escrita).
- Schema enforcement & evolution: evita que “qualquer JSON” bagunce o dataset.
- Time travel: voltar no tempo para auditar ou reproduzir análises.
- Upserts/Merge: atualizar e inserir dados de forma confiável.
Exemplo de uso
- Financeiro/ERP: corrigir registros (ex.: estorno) sem reprocessar tudo.
- Fraude e risco: manter histórico auditável para investigações.
- CDC (Change Data Capture): integrar mudanças de sistemas transacionais mantendo consistência.
- Streaming + batch no mesmo dataset, com qualidade. ✅ Legado: Delta Lake “recupera a confiança” no Data Lake e habilita governança técnica real.
5) Lakehouse – Um só dado para BI + Streaming + ML (sem duplicar tudo)
A Lakehouse surge quando a pergunta vira:
“Por que eu preciso de dois mundos separados — Data Lake para ciência/engenharia e Data Warehouse para BI?”
A proposta da Lakehouse Architecture é combinar:
- Escala e custo do Data Lake
- Confiabilidade e desempenho do Data Warehouse
- Unificação de workloads (BI, streaming, IA/ML) em uma única base governada
O que caracteriza uma Lakehouse “de verdade”
- Tabelas com camada transacional (ex.: Delta) sobre storage barato.
- Separação entre storage e compute (você escala processamento sem duplicar dados).
- Catálogo e governança (metadados, linhagem, permissões, masking).
- Camadas de curadoria (ex.: Bronze / Silver / Gold): Bronze: raw (como veio)
- Silver: limpo e padronizado
- Gold: pronto para consumo e métricas de negócio
Exemplo de uso
- BI (Power BI/Tableau) consumindo “Gold” com métricas consistentes.
- Streaming atualizando tabelas Silver quase em tempo real.
- ML extraindo features no mesmo lugar (sem exportar para outro repositório).
- Data Products por domínio (pensando em Data Mesh) usando o mesmo padrão de governança.
Resultado
- Menos duplicação (menos cópias e pipelines “espelho”).
- Menos retrabalho (uma definição de dado para múltiplos usos).
- Mais rastreabilidade e confiança. ✅ Legado: o Lakehouse é a tentativa mais madura de unificar análise, operação e ciência de dados em cima de um único “source of truth” bem governado.
Conclusão: não foi “moda”, foi maturidade
A história não é “Hadoop morreu” ou “Lakehouse substituiu tudo”. É mais simples (e mais real):
- GFS ensinou escala com falhas
- HDFS democratizou Big Data
- Data Lake trouxe flexibilidade e custo baixo
- Delta Lake trouxe transações e confiança
- Lakehouse trouxe unificação e governança para múltiplos workloads 📌 Frase para fechar o post com impacto:“O Lakehouse não substituiu o Data Lake — ele disciplinou o Data Lake.”


